
Search for: debricked


#146 – Att söka genom Github efter säkerhetsbrister
Att hitta spännande och bra projekt på Github är lätt, men att förstå om projektet är säkert, aktivt och jämförbart med andra projekt är betydligt svårare.
Det vet Emil Wåreus och hans kollegor på Debricked. Därför har de skapat produkten Open Source Select (prova här) som med hjälp av algoritmer analyserar projektet bland annat ur ett säkerhetsperspektiv som stöd för alla oss som arbetar med öppen källkod.
När det gått snett i verkligheten inom Open Source
I IT-säkerhetspoddens tredje, och sista, är Linus Karlsson (Security Specialist) från Debricked med oss och pratar om när det gått snett I verkligheten.
Riskerna att inte uppdatera Open Source och beroende applikationer
Ett vanligt fenomen är dåliga rutiner på att uppdatera sin mjukvara (eller dependencies som det benämns i avsnittet). Linus tar fallet med Equifax som exempel.
Equifax är ett stort kreditupplysningsföretag I USA som drabbades av en läckage där 145 miljoner människors information läckte. Ungefär hälften av USAs befolkning. Information som namn, adresser och körskortsuppgifter läckte.
Grundorsaken berodde på att Equifax nyttjade ett bibliotek, som är väldigt vanlig, som heter Apache struts. Biblioteket används för att skapa webtjänster baserat på Java.
Trots att Equifax upptäckte sårbarhet i Apache struts tog det ungefär ett halvår innan de presenterade detta. Anledningen vara att biblioteket inte uppdaterats och konsekvenserna blev att Equifax fick sitt varumärke svärtat samt att de fick betala tillbaka oerhört mycket pengar. De fick bland annat erbjuda gratistjänster till sina kunder.
Om man litar på A, som litar på B, betyder det automatiskt så att man litar på B?
Linus tar ett annat exempel som är mycket mer sofistikerat och som bygger på just att man litar på sin mjukvara och på så viss även litar på mjukvarans beroende program.
Den här gången drabbar det registryt NPM, eller rättare sagt Event Stream som är ett populärt paket bland java-script. Paketet gör en väldigt specifik grej, och i just detta fall, strömmar av event. Paketet är oerhört populärt och nyttjas i massor av mjukvara.
Event Streams skapare blir kontaktad av en okänd person som har ett antal förslag på förbättring och skickade dessa. Allt kändes som att personen agerade i all välmening. Förbättringarna godkändes, men ytterligare en dependencies smögs med. Det syntes men eftersom personen verkade schysst lade man ingen större notis om det, eftersom det inte innhöll något skadligt.
Men en månad senare uppdaterades just den här dependencies med ny kod. Den här gången skadlig!
Attacken var väldigt sofistikerad, och riktad, eftersom den skadliga koden aktiverades bara när mjukvaran hanterade Bitcoins. Dessutom om balansen på Bitcoin-plånboken hade hög likviditet. På så vis upptäcktes det inte lika lätt.

Konsekvenserna är okända men skadliga koden skeppas tillsammans med mjukvara för Bitcoin.
Hur kan man skydda sig mot detta?
I första exemplet gäller det givetvis att se till att ha en tydlig patchrutin. Mjukvaran ska vara uppdaterad. Man måste också ha koll på vilka beroenden som finns i mjukvaran och att även dessa är uppdaterade.
Det andra exemplet är knepigare eftersom det nästan är ett Social Engineering-attack där skaparen av mjukvaran luras att uppdatera sin kod. Ett tydligt svar finns inte riktigt utan det diskuteras fortfarande huruvida det är grundaren som var oansvarig medan en annan stor grupp tycker att man inte kan ha sådana förväntningar på en person som skapat mjukvaran på sin fritid. Dessutom en person som inte har tid att uppdatera mjukvaran längre.
Vem man ska lita på kanske inte är det viktiga utan mer mekanismen hur man tar in ny mjukvara, och upprätthåller den, i sin kod.
Machine learning inom Open source
I IT-säkerhetspoddens andra specialavsnitt är Emil Wåreus (Head of Data Science på debricked) tillbaka. Den här gången pratar vi om hans favoritämne – machine learning.
Att nyttja Maskininlärning har på sista tiden blivit betydligt billigare och det finns ramverk att arbeta med som kan tillämpas till sin mjukvara.
Säkerhetsföretaget debricked hanterar extremt mycket data i sitt analysverktyg för att identifiera sårbarheter i open source. Därför används maskininlärning för att processa all information.
Maskininlärning inte samma sak som AI
Emil har tidigare byggt robotar (eller autonoma agenter), till exempel drönare som följde efter människor, och där noterade han att begreppet maskininlärning missförstås. Ofta blandas det ihop med AI fast det är helt separata saker. Så för att förtydliga:
- AI kan beskrivas, ur ett autonom-agent-perspektiv, som human, det vill säga en agent som kan förstå sin omgivning och ta beslut helt utan styrning.
- Maskininlärning däremot, ur samma perspektiv, kan delvis uppfatta omgivningen men är bättre på varseblivning. Den fungerar väl i en stängd miljön men om man tar drönararbetet som exempel är omgivningen fysisk. Maskininlärning som teknik kan då inte “förstå” omgivningen men däremot analysera bilder. Problem kan uppstå där till exempel maskininlärning kan tro att en ko kan vara i en hästhage (där ett AI, som förstår omgivningen, förmodligen skulle anta det är en häst eftersom den förstår att det är en hästhage). Det är således viktigt att träna sin maskininlärning.
Processad information måste bli rätt
Vi tar oss an den amerikanska databasen NVD igen, där Emil upptäckte att sårbarheterna som presenterades var missvisande.
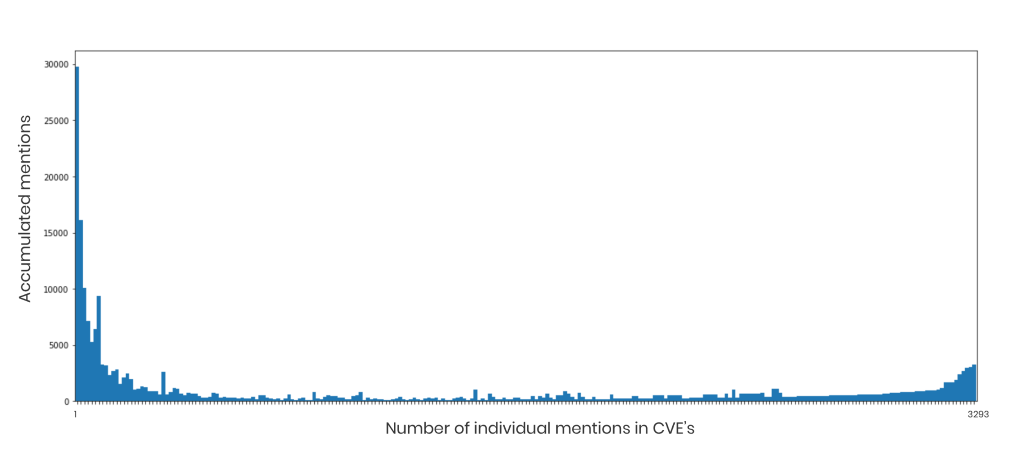
Sårbarheter presenteras som att 60% av produkter som visas endast har en sårbarhet och 90% med under sex sårbarheter. Det blir alltså svårt att se allvarligheten i de olika mjukvarorna och vilka projekt som innebär störst risk att nyttja.
Debricked tar hjälp av sin egen maskininlärningsalgoritm för att samla NVD tillsammans med issues på Github (repository med mjukvaror) för att få kvalité på informationen. Den tittar till exempel på språkbruket i skapade issuen och vad för ord som den innehåller för att bilda sig en uppfattning. På så vis kan algoritmen avgöra vad som är en säkerhetsbrist och vad som till exempel är en bugg.
Den guidar utvecklare i rätt riktning och att göra rätt.
Algoritmen läser miljoner rader av text (från flera olika repositories) och förstår och kategoriserar problemet.
Träna sin algoritm
Maskininlärning måste hela tiden tränas på sådant den känner till och på sådant den inte känner till. Tekniken kallas Semi-supervised learning och där använder debricked Googles TensorFlow.
Vi återanvänder häst-exemplet. Emil tränar sitt dataset med ett antal bilder på hästar och sådant som är markerat som “inte häst”. Sedan massor av bilder på sådant som är helt okänt. Algoritmen processar bilderna och förstår, och blir ännu mer träffsäker, på vad som är en “häst i en bild”.
Det finns färdigtränade algoritmer för till exempel bildanalys och text men inte mycket för att upptäcka säkerhetsbrister. Där är debricked ledande och slår andra som gör liknande.
Vad är en säkerhetsbrist?
Debrickeds algoritm kan läsa nästan vilken text som helst och avgöra om det är ett säkerhetsproblem som beskrivs eller inte. Företaget arbetar vidare med att kategorisera vikten av hur allvarlig bristen är.
Emil poängterar vikten att förstå sitt område som dataanalytiker. Man måste kunna till exempel säkerhet för att kunna utveckla maskininlärning som hanterar säkerhet. Man måste hela tiden jobba och undersöka hur träffsäker sin maskininlärning är. Det går inte att ha en algoritm som förutspår sju av tio fel och genererar för mycket falska larm (false positive). Det är viktigt att den data som levereras till kund är minst över 90% korrekt, så kunden kan fokusera på rätt saker.
Avslutande tips
Emil avrunda med tips inom maskininlärning
- Det är viktigt att ha låg false positive men att arbeta med att öka informationen att ta in utan att sänka kvalitén med hög träffsäkerhet
- Arbeta med erkända ramverk (t.ex. TensorFlow)
- Arbeta med matematiken för att optimera effektivt och för att förstå sin data
- Förstå din domän först (område) som maskininlärningen ska hantera
- Maskininlärning är ett medel för att nå ditt mål
Lösa trådar – eller vad händer just nu?

Ibland känner jag för att bara skriva några tankar i största allmänhet om vad vi gör på denna podd, så det tänkte jag göra här.
Januari är över och februari känns som april rent vädermässigt. Podden går framåt med stora steg. Vi kom igång riktigt bra efter sommaren med många intressanta intervjuer. Och hela tiden har lyssnarantalet långsamt men säkert ökat. Intervjuerna drar mycket nytt folk som kanske är intresserade av personen vi pratar med eller fått veta om oss via personens sociala medier. De vanliga snacken är också populära. Att försöka gissa vad som lockar mest kan vara en utmaning, men vissa mönster kan skönjas. Enligt min högst personliga åsikt verkar det, som jag sagt tidigare, ha varit en bra idé att börja väva in fler historier i snacket,. Att blanda mer tekniska avsnitt med avsnitt som tar oss in i närliggande områden fungerar också vad det verkar. När vi pratade om Nordkorea, kunde vi bjuda på en genomgång av hackergrupperna som är kopplade till landet och samtidigt ha en diskussion om varför man hackar och vilken relation man har till resten av världen. Vi kom till och med in på ämnet ”Käre ledare”, en känd bok skriven av en politisk flykting med inside-information från Nordkoreas ledning.
Vi har också samarbetat med SIG Security, vilket gjort att ni kunnat följa deras föredraghållare som berättat om sina favoritämnen. Det blev till och med en radioteater där ostoppbar entusiasm för molnet mötte skeptisk motkraft som manade till försiktighet. Och i ett annat avsnitt fick vi veta om vad som snart kanske blir en molncertifiering som backas av EU.

Vi stötte flera gånger på ämnet retrodatorer och hackarna som älskade dem. Jörgen Nissen berättade om de ungdomar som växte upp med hemdatorn. Pontus Berg, också känd som Bacchus från Fairlight, tyckte det handlade lite för mycket om att bryta sig in i system när vi pratade om dåtidens hackare och kom själv istället med en mycket intressant berättelse om dåtidens demoscen och spelpirater. Det blev tillsist nästan en serie om en svunnen tid som ändå var alldeles nyss.
När julen stod för dörren samlade vi ihop årets olika diskussioner som att lita på varandra till ett avsnitt om digital trust. Nyårsavsnittet sammanfattade allting och introducerade termen ”bläord”. Alltså sådant där som man har hört någon gång för mycket. 2018 års nyårsavsnitt förutspådde ju a AI skulle vara hett och nu landade termen istället som just ett ”bläord”.
Och vad händer i vår?
Vi har kört igång en miniserie på tre avsnitt i samarbete med Debricked som handlar om open source och vad en utvecklare behöver tänka på för att hålla allting så säkert som möjligt.
Intervjuerna fortsätter och vi jagar ständigt intressanta personer som kan ge sina högst personliga insikter inom säkerhetsområdet.
Och vi har inte glömt att nörden måste få vara med. Det kommer bli avsnitt där vi går ner på djupet i ämnen. Senast var det ju brandväggen, där vi ställde upp den klassiska brandväggen mot proxyn och lät dem gå en ”boxningsmatch” i tre ronder.
Vi håller redan på att dra i trådarna för att få tag på vårens talare på SIG Security och kommer fortsätta samarbeta med dem under hela 2020.
Det blir en intressant och lärorik vår här på IT-säkerhetspodden.
Statistik inom Open source
Affärsmodell med Open source
Allt fler företag väljer att skapa mjukvara baserat på öppen källkod (Open source). I IT-säkerhetspoddens avsnitt pratar vi med Emil Wåreus Head of Data Sience på debricked om risker kopplat till öppen mjukvara och statistik (eller fun facts).
Statistiken är viktig att förstå för att välja rätt öppen källkod och hur komplext det kan vara för att undvika säkerhetsrisker.
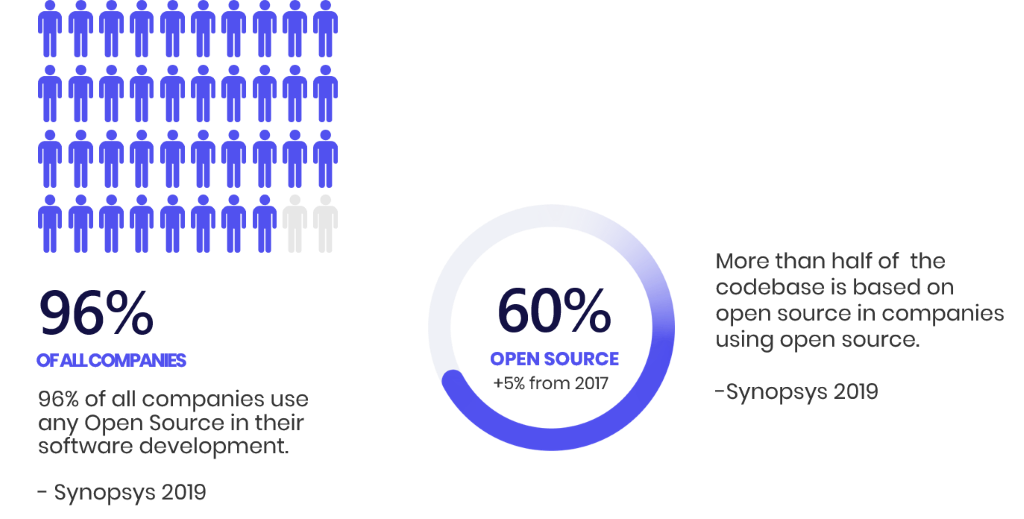
Öppen källkod kan jämförs som en rörelse där skapare nyttjar öppen källkod och publicerar sina anpassningar på internet för hela Open source-scenen. Engagemanget är stort och förslag med funktionell och säkerhetsmässiga förbättringar diskuteras inom rörelsen.
Det kan tyckas märkligt att företagare lämnar ut sin affärsidé och delar med sig till vem som helst och för att förstå hur det hänger ihop tar vi oss till 80-talet. Trenden var då att man såg sin mjukvara just som själva affärsidén. Resultatet blev en statisk mjukvara (eller proprietär kod) med ett hackigt community. .
Open source startade samtidigt på konsumentsidan där engagemanget blev stort bland användare. När det nu är utbrett på företagssidan är en vanlig affärsmodell open core där kärnan är öppen medan tilläggstjänster såsom support och konsultarbeten blir affärsmodellen. På så vis behålls engagemanget i Open source och samtidigt kan företagare vara lönsamma genom att hjälpa sina kunder med vad de faktiskt efterfrågar.
Flera hundra beroenden
Det många inte vet är att en öppen källkod ofta inte är just en mjukvara. Tvärtom. Vanligare är snarare att mjukvaror använder flera hundra direktimporterade mjukvaror som den är beroende av. Beroenden med sina egna öppna källkod och sårbarheter. Emil Wåreus tar ramverket React som exempel som är en plattform baserad på Java och skapat av Facebook. Verktyget är väldigt populärt just nu för att skapa webapplikationer och bygger på just öppen källkod. Men få känner till att React har ungefär 3.500 beroenden. Hur ska man ha koll på vilka man använder och vilka säkerhetsrisker det finns att nyttja ett sådant ramverk?
Här finns fördelen med den öppna källkodsscenen där man kan ta del av andras upptäckter och idéer till skillnad mot stängd mjukvara där tillverkaren ansvarar för att upptäcka sårbarheter och täppa till dessa.
För att reda ut svårigheterna finns debrickeds mjukvara som analyserar mjukvaran inom tre områden – sårbarheter, licensieringen och hälsokontroll (health check), där det sistnämnda undersöker just communityt för att analysera hur högt engagemanget såsom bidragande medlemmar. Det hela poängbedöms av debricked vilket hjälper upphovsmakarna att välja rätt öppen källkod.

Flera datakällor för att upptäcka sårbarheter
Debricked är integrerat med Amerikanska NISTs “National Vulnerability Database” (NVD) som är en öppen databas där man kan hitta kända sårbarheter i öppen källkod. Här rapporterar communities (till exempel Github) till NVD för analys. NVD undersöker vilken typ av sårbarhet som avses och om det är kopplat till säkerhet eller inte. Ungefär femtio nya sårbarheter registreras – per dag!
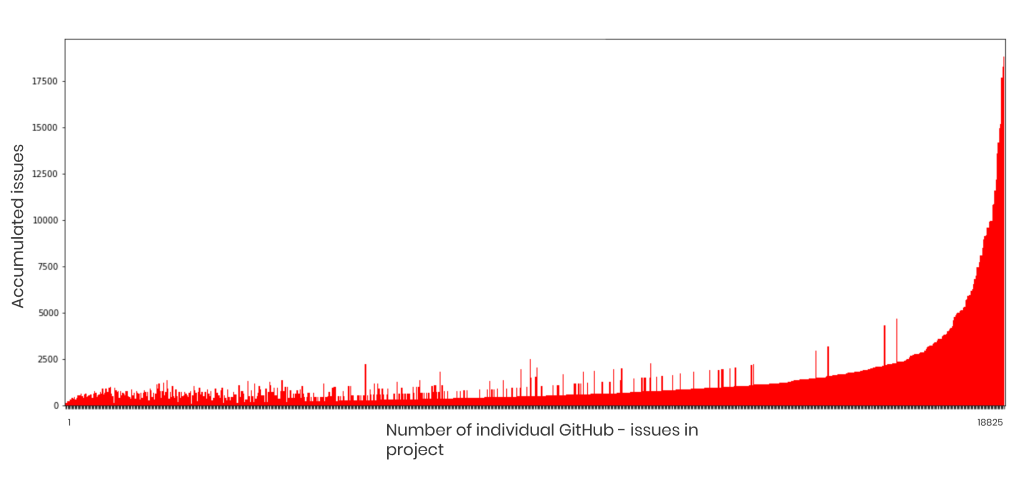
Statistik från NVD visar vilka projekt som innehåller mest sårbarheter. Bild nedan visar de högst rankade just nu.

Men NVD räcker inte för att upptäcka sårbarheter så därför är databasen bara en av datakällor som debricked nyttjar. En stor del upptäcks inte eftersom NVD har koll på 50.000 projekt som har ungefär 120.000-130.000 sårbarheter. Debricked däremot hittar över 200.000 sårbarheter relaterat till säkerhet eftersom de samlar in från flera datakällor.
Den andra stora källan är, numera Microsoft-ägda GitHub, som debricked nyttjar som datakälla. Här undersåker debricked så kallade issues på Github.
Om man skapar en enkel websida baserad på öppen källkod med populära verktyg och installerar enligt standard kan man räkna med ungefär 10.000-15.000 beroende mjukvaror med hundratals sårbarheter. Nästa steg blir att analysera sårbarheten som oftast (ungefär 30%) kan täppas till genom att uppdatera. Men resten är klurigare. Man ska ställa sig frågan – använder jag den här mjukvaran? Eller kan jag bygga runt det på något vis?
Fyra råd
Emil Wåreus ger fyras råd för öppna källkodsprojekt.
- Använd debricked tidigt i processen innan du importerar mjukvara för att förstå hur säker den är och undersök poängbedömningen.
- Sätt policys för att blockera osäker mjukvara. På så vis hjälper man utvecklare att göra rätt och förhindra att fel kod importeras
- Räkna på mjukvaran som är tänkt att användas. Räkna hur mycket tid och pengar det krävs för att säkra mjukvaran
- Använd inte gammal mjukvara
Man får också väga “springa framåt” mot “håll tätt bakåt” i projektet.
Senaste kommentarer