
I IT-säkerhetspoddens andra specialavsnitt är Emil Wåreus (Head of Data Science på debricked) tillbaka. Den här gången pratar vi om hans favoritämne – machine learning.
Att nyttja Maskininlärning har på sista tiden blivit betydligt billigare och det finns ramverk att arbeta med som kan tillämpas till sin mjukvara.
Säkerhetsföretaget debricked hanterar extremt mycket data i sitt analysverktyg för att identifiera sårbarheter i open source. Därför används maskininlärning för att processa all information.
Maskininlärning inte samma sak som AI
Emil har tidigare byggt robotar (eller autonoma agenter), till exempel drönare som följde efter människor, och där noterade han att begreppet maskininlärning missförstås. Ofta blandas det ihop med AI fast det är helt separata saker. Så för att förtydliga:
- AI kan beskrivas, ur ett autonom-agent-perspektiv, som human, det vill säga en agent som kan förstå sin omgivning och ta beslut helt utan styrning.
- Maskininlärning däremot, ur samma perspektiv, kan delvis uppfatta omgivningen men är bättre på varseblivning. Den fungerar väl i en stängd miljön men om man tar drönararbetet som exempel är omgivningen fysisk. Maskininlärning som teknik kan då inte “förstå” omgivningen men däremot analysera bilder. Problem kan uppstå där till exempel maskininlärning kan tro att en ko kan vara i en hästhage (där ett AI, som förstår omgivningen, förmodligen skulle anta det är en häst eftersom den förstår att det är en hästhage). Det är således viktigt att träna sin maskininlärning.
Processad information måste bli rätt
Vi tar oss an den amerikanska databasen NVD igen, där Emil upptäckte att sårbarheterna som presenterades var missvisande.
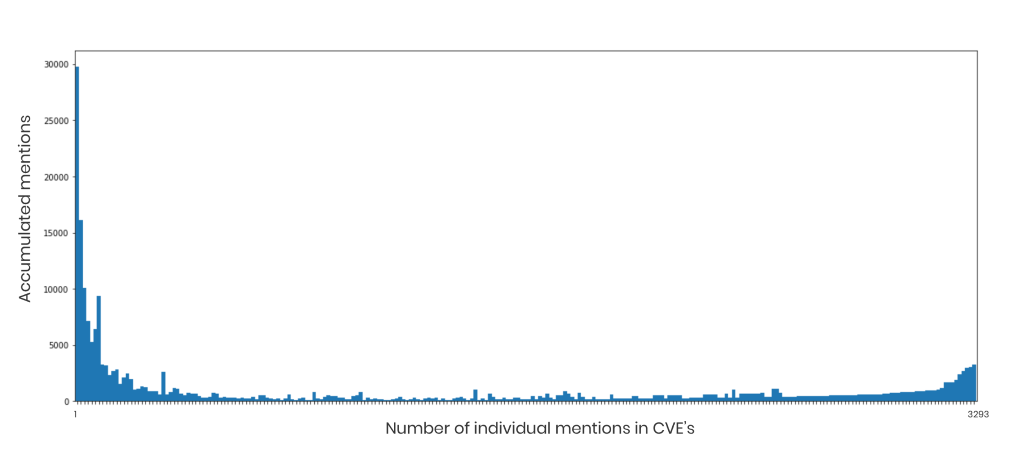
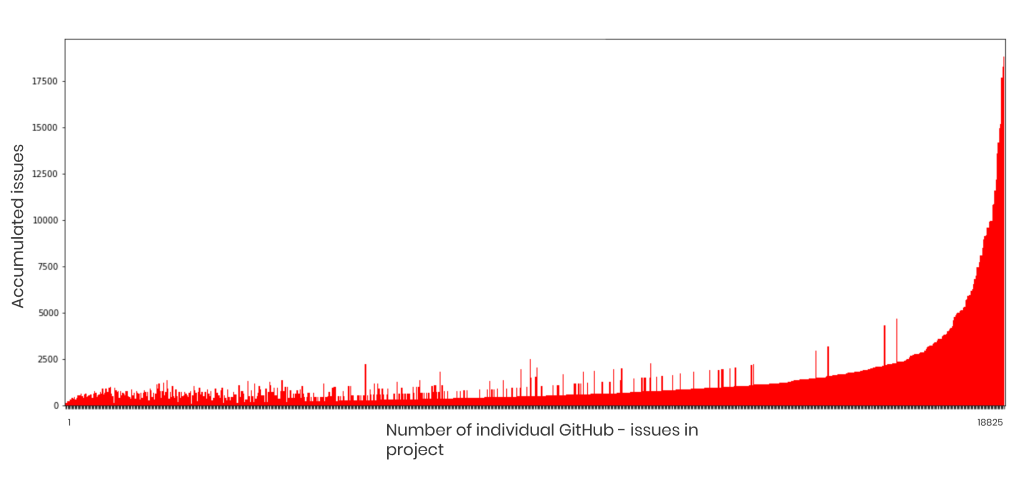
Sårbarheter presenteras som att 60% av produkter som visas endast har en sårbarhet och 90% med under sex sårbarheter. Det blir alltså svårt att se allvarligheten i de olika mjukvarorna och vilka projekt som innebär störst risk att nyttja.
Debricked tar hjälp av sin egen maskininlärningsalgoritm för att samla NVD tillsammans med issues på Github (repository med mjukvaror) för att få kvalité på informationen. Den tittar till exempel på språkbruket i skapade issuen och vad för ord som den innehåller för att bilda sig en uppfattning. På så vis kan algoritmen avgöra vad som är en säkerhetsbrist och vad som till exempel är en bugg.
Den guidar utvecklare i rätt riktning och att göra rätt.
Algoritmen läser miljoner rader av text (från flera olika repositories) och förstår och kategoriserar problemet.
Träna sin algoritm
Maskininlärning måste hela tiden tränas på sådant den känner till och på sådant den inte känner till. Tekniken kallas Semi-supervised learning och där använder debricked Googles TensorFlow.
Vi återanvänder häst-exemplet. Emil tränar sitt dataset med ett antal bilder på hästar och sådant som är markerat som “inte häst”. Sedan massor av bilder på sådant som är helt okänt. Algoritmen processar bilderna och förstår, och blir ännu mer träffsäker, på vad som är en “häst i en bild”.
Det finns färdigtränade algoritmer för till exempel bildanalys och text men inte mycket för att upptäcka säkerhetsbrister. Där är debricked ledande och slår andra som gör liknande.
Vad är en säkerhetsbrist?
Debrickeds algoritm kan läsa nästan vilken text som helst och avgöra om det är ett säkerhetsproblem som beskrivs eller inte. Företaget arbetar vidare med att kategorisera vikten av hur allvarlig bristen är.
Emil poängterar vikten att förstå sitt område som dataanalytiker. Man måste kunna till exempel säkerhet för att kunna utveckla maskininlärning som hanterar säkerhet. Man måste hela tiden jobba och undersöka hur träffsäker sin maskininlärning är. Det går inte att ha en algoritm som förutspår sju av tio fel och genererar för mycket falska larm (false positive). Det är viktigt att den data som levereras till kund är minst över 90% korrekt, så kunden kan fokusera på rätt saker.
Avslutande tips
Emil avrunda med tips inom maskininlärning
- Det är viktigt att ha låg false positive men att arbeta med att öka informationen att ta in utan att sänka kvalitén med hög träffsäkerhet
- Arbeta med erkända ramverk (t.ex. TensorFlow)
- Arbeta med matematiken för att optimera effektivt och för att förstå sin data
- Förstå din domän först (område) som maskininlärningen ska hantera
- Maskininlärning är ett medel för att nå ditt mål