
Show Notes för #100 – Säkerheten i HP SureClick

Avsnittet heter #100 – Säkerheten i HP SureClick
Det spelades in 2020-10-25 och lades ut 2020-11-15.
Deltagare: Erik Zalitis och Mattias Jadesköld
Show notes skrivna av Erik Zalitis.
Vi är ju normalt inte en ”videopodd”, så detta har varit en utmaning för oss. Jag har jobbat med ljudet och Mattias med bilden. Så här vårt första videoavsnitt där vi båda deltar. Vi kan inte lagra stora filer på Libsyn där vi skickar ut våra poddar, så avsnittet med video finns på YouTube och det med ljud finns där poddar finns (eller på denna sida).
HPs dator har ett antal säkerhetsfunktioner och vi har valt att gå igenom dem en och en för att se vad de klarar och var de inte räcker hela vägen.
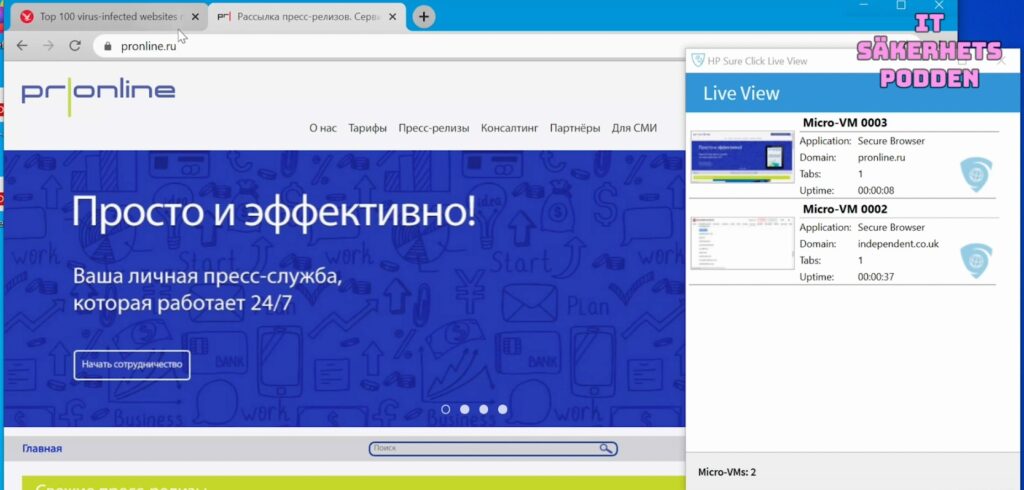
Så till HP SureClick. Det lovar att den kan göra att din webbläsarsession körs i ett säkert läge, eller en ”detonationskammare” som jag kallar det. Effekten av en attack är att webbläsaren inte öppnar en väg in till resten av datorn, vilket annars kan leda till att ransomware får fotfäste, kryptobrytare får köra eller datorn kan tas över. När du stänger webbläsaren, raderas allt i den, vilket också avbryter all körande skadlig kod. Men allt du gör i webbläsaren i sig är inte säkert om någon tar över den och det du håller på med. Vilket kan vara banktransaktioner eller sessioner mot andra servrar eller ditt tillgång till ditt Facebook-konto.
Dessutom fungerar SureClick enbart med den inbyggda säkra webbläsaren som är en Chromium-klon vilken HP själva uppdaterar… ibland… Den äldre versionen av HP Sureclick lovade uppdateringar varje halvår. Detta är sällan och mycket oroande. När vi började testa, kunder Mattias konstatera att versionen av Chromium som du måste använda var 10 versioner efter den senaste som släppts. Chromium är ju också vad ”Google Chrome” är byggt på och den webbläsaren är troligen den mest eftertraktade att hacka för cyberbrottslingar.
Mitt under testet kom en ny version som lovar fler uppdateringar, men också tar bort stödet för alla andra webbläsare än den säkra.
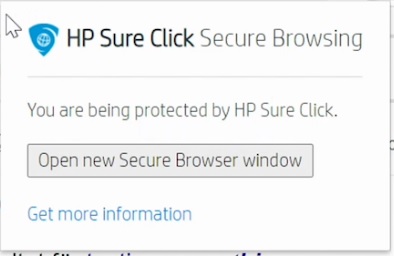
Rutan ovan finns i tillägget som är installerat i riktiga Google Chrome, som du kanske laddar ner och installerar på datorn, och det lovar dig säkerhet… Men det är inte sant, du måste klicka på ”Open new Secure Browser window” för att den säkra webbläsaren ska starta. Direkt vilseledande och garanterat att få folk att tro att de är säkra när så inte är fallet. Katastrofalt dåligt!
Borde man överhuvudtaget tillåta att köra saker utanför denna SureClick-funktion? Jag påpekar i avsnittet dumheten med ett säkerhetsskydd som man slår av och på hela tiden beroende på vad man gör.

Mattias valde att ställa upp SureClick mot det 15 vanligaste säkerhetshoten just nu. Vi går igenom dem steg för steg och snackar om de som är relevanta för diskussionen. Det är värt att notera, som jag skrev i början, att SureClick bara är EN av många funktioner som skyddar maskinen. Vi kommer givetvis ställa upp de andra säkerhetsfunktionerna mot hoten. Så i sin helhet kan datorn hantera fler hot än vad SureClick i sig själv klarar av. Men denna lök ska ju skalas, så det är vad vi gör i detta avsnitt.




Senaste kommentarer