

Skrivet av Erik Zalitis
”Det finns inga genvägar till det perfekta ljudet” säger ju farbror Barbro, och henom måste ju ha rätt eller hur? Faktum är att jag inte håller med. När man arbetar med ljudteknik, hittar man snabbt just genvägar för att göra att det låter bra och går så effektivt som möjligt att spela in.
Så låt mig berätta exakt hur IT-säkerhetspodden spelar in ljud och ser till att det kommer ut på nätet. Efter detta kommer ni förstå att det är allt annat än att bara sätta upp en mick på ett bord och sedan bara snacka på. Visst kan man göra så, men det blir därefter.
Låt mig därför ta dig med på en berättelse om hur vi spelar in ett avsnitt från när den feta duffelväskan med ljudutrustningen åker fram tills Libsyn publicerar det färdiga avsnittet.

Alltid mobil – alltid redo

En del poddar har lyxen att ha en studio och andra hyr en. Men vi är alltid mobila. Ge oss ett hyggligt tyst rum och vi är redo att spela in på några minuter. Det har ingen betydelse om det är jag och Mattias eller om vi har en eller flera deltagare.
En del gäster möter vi på deras jobb eller i en lokal som vi fixar fram själva. Andra intervjuas via Teams, Zoom eller annan konferansprogramvara. Detta är mycket vanligt nu i Coronatider.
Duffelväskan innehåller portabla mickstativ, tre mickar, en bandspelare, kablar och hörlurar. Många kopplar mickarna till en dator och lägger på effekter i realtid under inspelningen. Vi gör all processing i efterhand. Så det enda man måste göra under inspelningen är att justera ljudnivåerna och lyssna på att folk hanterar mickarna rätt.
När man rattar ljudet måste man konstant vara redo att korrigera fel som uppstår. Folk riktar sig bort från mickarna, prasslar med papper och fläktar går igång helt plötsligt utan förvarning.
Mattias brukar skämta om hur petig jag är med att folk ska sitta rakt framför mickarna, hålla händerna stilla och inte vrida på sig hela tiden. Om man inte håller pli på alla, går det sen inte att rätta till de störljud som uppstår i efterhand.
Dessutom måste man kompensera för hur folk pratar. Jag har en dynamisk röst som går upp och ner i ljudstyrka. Mattias har en mycket mer jämn röst, men har en tendens att ibland prata vädligt tyst, nästan viska. Sedan drar han in luft i lungorna och tar i så att mätarna går i taket. Man lär sig snart att lyssna efter hur folk pratar och förutsäga hur man ska justera nivåerna. Intervjuoffren är ett värre problem. Man vet inte hur de kommer använda sina röster. Några pratar med samma röstläge hela tiden, medan andra går mellan tordönstämma och tyst som en mus.
En digital ”bandspelare” är också en knepig sak. ”På min tid”, som vi gubbar gillar att säga, var det mesta analogt. En analog bandspelare tål måttlig överstyrning utan att det låter för dåligt. En digital gör det inte. Så fort du når ”nollan”, finns inga fler bitar kvar för att beskriva ljudet och då blir det blixtsnabbt svårt distorderat om man inte drar ner volymen när någon höjer rösten.
Men låt oss tala om utrustningen…

Bandspelaren: Zoom H6
När vi startade podden, plockade jag fram allting jag hade kvar från mina närradiodagar. Bland annat en digital Fostex Portastudio. Men jag var orolig för att den 16 år gamla maskinen skulle ha problem med sina åldrade CF-Kort och dessutom kändes den fel för ändamålet då den är mer menad för musiker och hade rätt lite spelrum för svårdrivna mickar. Så jag började kolla runt och Zoom H6 blev mitt val. Den är en märklig tingest som har fyra XLR-kontakter för mikrofoner med fantommatning och en mick-preamp med mycket gott headroom. Dessutom kan den expanderas med mickhuvuden eller två extra mikrofon-kontakter. Och den har en tydlig display som kan drivas på batterier och har multikanalinspelning för varje mikrofon. Den är lite dyrare än många andra liknande enheter, och det blev ju något jag fick stå för själv då vi inte hade några pengar för att göra podden. Men den fungerar fantastiskt. Dock är preampen något brusig när man går över sjuan på inspelningsnivån. Så den fungerar bäst med lättdrivna kondensatormickar eller närmickade dynamiska.

Mikrofonerna ett och två: AKG C1000
Kondensatormickar förr i tiden var dyra och det fanns få som var bra i det billigare segmentet. C1000 var en av de första semi-proffsmickarna av kondensatortyp som var riktig vettiga enligt min åsikt. De är något av ett tveeggat svärd, då de är känsliga, lättdrivna, låter mycket bra men kan även distordera vid närmickning.
Mattias och jag sitter framför varsin sådan när vi pratar.
Mikrofon tre: Shure SM58
Shure SM58 är mikrofonernas Volvo. En duglig och vettig sådan som i sin design är okänslig, trubbig och är rätt medioker på att återge detaljer. Men för tal fungerar den pålitligt. Den kompenserar för ”proximity effekten”, alltså basökningen när man närmickar. Detta fungerar dock inte så bra i verkligheten, så man får ta med det i beräkningarna när man processar ljudet.
Det går att höra i en del avsnitt när vi är fler än två att den som får SM58an låter något mer bullrig och har en högre medelnivå på signalstyrkan på talet. Hint: det är oftast jag eller Mattias som använder den för att gästerna ska ha samma förutsättningar.
Pengar börjar nu komma in till podden och så, men vi vet att inte slösa. Så dessa mickar, som är mina privata, får vara kvar då de fungerar bra och är pålitliga.
Redigering
Det finns många program för ljudredigering därute, men vi spelar ju in allting på Zoom-bandspelaren och för sedan över det till min bärbara där redigeringen sedan sker. Jag kan även göra det mesta jobbet via min stationära hemma.
Offline-metoden att skapa programmen gör att man aldrig gör ett slutgiltigt beslut. Skulle jag vilja göra om ett avsnitt eller så i framtiden, kan jag göra om allting utan att behöva bry mig om hur filter och effekter lades på vid förra redigeringen. Alla originalfiler redigeras icke-destruktivt och mastras till en .wav och en .mp3-fil. Så om någon vill ha ett utdrag, kan jag alltid ge dem möjligheten att själva bestämma slutresultatet.
Kravet på ett ljudprogram där man offlineredigerar är inte så stora, så gratisprogrammet Audacity räcker för oss. Dyrare program gör det ofta möjligt att spela in flera kanaler samtidigt direkt i datorn med effekter pålagda i realtid. Men vi jobbar ju inte så…
Att skapa ljud är att veta i förväg hur det ska låta. Jag är en radionörd och lyssnar ofta på Sverige Radios ljud och försöker hitta inspiration för hur det ska låta. De har bra mycket bättre utrustning än vad vi kan drömma om, men det går att gissa hur de tänker och ta efter. Men givetvis blir det inte samma ljud. Jag tror tricket är närmickning, mycket limitering, peta på lite mer diskant och försöka se till att ljudnivåerna jämna och starka så att podden hörs bra i bilen eller i mobilen på tunnelbanan. Detta gör att jag offrar klarhet, dynamik och korrekt röståtergivning för kraft, intensitet och närhet i ljudet. Men ibland gör det faktum att vi alltid är mobila det svårt att få studiokänsla i ljudet. Det ligger i sakens natur. Dock är jag noggrann med att det alltid ska låta så bra att man kan leva med lite ”på fältet-känsla” med rumsakustik och bakgrundsljud.
Processning
Innan redigeringen börjar jag med att lägga till vinjetten och justera starten på talet så den hamnar korrekt i slutet av den. Sedan går jag på varje deltagares kanal och går igenom följande steg tills alla deltagarnas röster låter bra:
Steg 1 – Upplättning av diskanten
Det blir lätt burkigt ljud när man spelar in. Jag lättar upp diskanten med några dB för att få en bättre ljudbild. Detta gör att rösterna blir ”piggare”. När jag lyssnar på andra poddar, märker jag de inte verkar göra detta. Det gör att vi låter bättre och mer professionella. Men det är inte gratis, denna ökning skapar en tendens till skarpa S-ljud. Mer om hur vi fixar detta lite senare.
Steg 2 – Limitering / komprimering
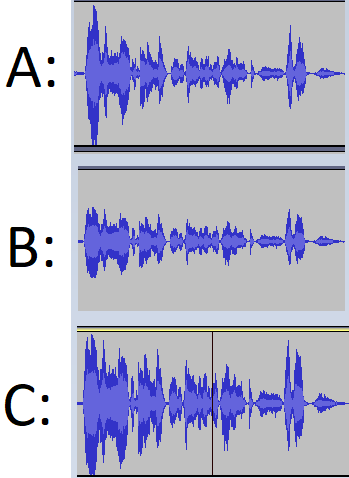
Ljudkurvorna ovan visar ljudstyrkan i Y-axeln och tiden i X-axeln. Högre staplar = starkare ljud.
Jag börjar med originalljudet från bandspelaren (A), komprimerar sedan det så man minskar skillnaden mellan de svaga och starka delarna av ljudet och plattar således till topparna (B). Till sist normaliserar jag ljudet för att kompensera för de förlorade topparna (trycker upp ljudpaketet). Resultatet blir ett ljud med större kraft, intensitet och som även hörs bra när man lyssnar på det i en brusig miljö. (C).
Ok, låt mig förklara. Komprimering av ljud har ingenting med Mp3-filer och sånt göra, det är i sig en annan sak som också kallas komprimering. Det jag pratar om är när man minskar skillnaden mellan de starka och de svaga partierna i ljudet. Man trycker som sagt ihop det. I extremfall skulle man kunna säga att en hårnål som slår i golvet och en atombomb som briserar skulle kunna låta lika högt i dina hörlurar. ”Loudness wars” dök upp när ljudtekniker som mastrade musik för CD-skivor hårdkomprimerade ljudet för att det skulle låta starkare och ge mer tryck i högtalarna eller överrösta andra källor. Det pratades också om att låga inspelningsnivår på ett digitalt media ledde till problem med upplösningen av ljudet med kvantiseringsbrus och anti-aliasing som följd. Detta är inom rimliga nivåer rent nys, anser jag.
Audiofiler HATAR ljudkomprimering. Limitering är en mycket kraftig komprimering som kan skapa mycket problem med dynamiken. Och the ”Loudness wars” är en stor källa till ilska bland audiofiler som anser att det förstörde CD-skivan på 90-talet.
Men radion älskar kompressorer och limiters. Dessa gör att en bra röst kan dåna över FM-radions brus, kortvågens atmosfäriska störningar eller andra situationer där signalen är tvungen att höras bra. IT-säkerhetspodden är inspelad och mastrad som den vore en riktig radiostation eftersom det är så jag lärt mig göra det. Vi har ofta en märkbart högre ljudnivå än de flesta andra poddarna jag jämför med och många Youtube-klipp. Detta kommer med konsekvensen att vi inte alltid låter lika rent, naturligt och äkta. Uppoffringen är lätt att göra, för att jag anser att det är precis så jag VILL att det ska låta.
Steg 3 – Normalisering / DC offset
Direkt efter limitering är ljudet alltid lägre än innan. Om jag minskar topparna, kommer ”ljudpaketet” att bli tätare när de försvinner. Normaliseringen höjer sedan det kvarvarande ljudet så dess högsta delar går upp till den högsta möjliga ljudnivå som är möjlig. På detta sätt trycker vi först ihop ljudet och sedan skruvar vi upp det så långt det går så att signalförlusten försvinner. Resultatet blir ett intensivare ljud som ”ligger på topp”.
DC-justeringen ser till att korrigera om signalen är förskjuten på grund av på grund av en felaktig likspänningsnivå. Detta är sällan ett problem, men bra att göra.
Steg 4 – De-essing med Soothe2
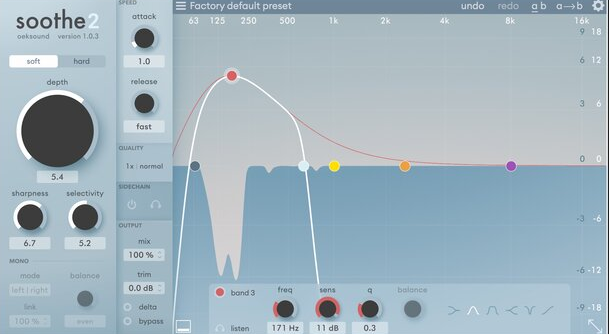
Minns du att jag skrev att S-ljuden blir starkare efter min ökning av diskanten? Detta kan vara otrevligt att lyssna på. Fenomenet kallas på Engelska för ”sibilance”. Så vi måste hantera detta. Fram tills för några veckor sedan kunde vi inte göra så mycket åt det, så vi fick vara försiktiga med att öka diskanten för mycket. Då köpte jag programmet Soothe2, en multibandskompressor i mjukvara med profiler för en hel del intressanta effekter. Bland annat ett antal de-essers.
En de-esser är enkelt uttryckt en kompressor/limiter som arbetar på en mycket begränsad del av ljudet. Man trycker bara ner det runt just de frekvenser där s-ljudet ligger. Detta gör att talet inte blir så vasst.
Denna process håller jag på att förfina just nu. De-essing infördes första gången på avsnittet #80 – Säkerhet kring utdöd teknik.
Steg 5 – Hantering av rumsakustiken och min tunga andning

Alla rum som inte är byggda som studios har en rumsakustik. Om väggarna är raka (vilket de är i normala rum), studsar ljudet mellan dem och det bildas en stående våg. Vi har ju ingen studio och vi är inte alltid samma lokal. Så en viss rumsakustik är att vänta. Närmickning och att mickarna har en tillsats som ger dem en smalar upptagningszon (”Karaktäristik”) minskar problemet i någon mån.
I och med att varje mikrofon har en egen kanal som blir en egen ljudfil i bandspelaren, kan man filtrera ut den kanal som inte används för stunden. Detta minskar rummets inverkan ordentligt. Jag har en tung andning som kräver att jag tystar min mikrofon när jag inte talar. Detta gör jag i efterredigeringen och har ännu inte kommit på hur man automatiserar det på ett tillförlitligt sätt. Så detta är nog den delen som tar längst tid att genomföra.
Steg 6 – Tätning av pratet: hur man får en rappare konversation
Tänk att du lyssnar på ett avsnitt av IT-säkerhetspodden och diskussionen går såhär:
Erik: – ”Om man tänker på …. ehh….. hur … vad heter det nu …. hur … hur … Burp suite kan användas för att göra SQL-injekti…. injections… snabbare att hitta, måste man förstå att konceptuellt sett…”
Mattias: – ”Alltså du tänker på … hur … man … alltså .. kan … göra det mer … eh…”.
Erik: – ”Automatiskt?”
Mattias: – ”Just det… Kan man då säga att det blir mer … mer tillför…eh…litligt”
Såhär skulle en konversation kunna låta i ett program och det är normalt. Och till viss del måste det ju få göra det – ingen pratar i skriftspråk. Men det är ändå en viss fördröjning mellan ord när vi försöker komma på hur meningen bör avslutas eller letar efter lämpliga ord.
Beroende på trötthetsgrad, stress och hur våra diskussioner ofta kan komma in på sidospår som vi inte förberett för, blir det ibland lite för mycket stapplande eller letande efter hur vi ska uttrycka oss. Och det kan till sist bli irriterande att lyssna på.
Förut klippte jag enbart uppenbara omtagningar eller extremt långa pauser. Nu lägger jag ner på tid att klippa i meningar och mellan dem för att få dem rappare och ta bort tunga inadningar och onödiga repetitioner.
Detta är svårt, då det ibland rent av inte går. Om man tar bort ord mitt i en mening kan talrytmen bli fel. Det låter helt enkelt bara konstigt. Om någon uttalar ett ord fel två gånger på rak, gör de ofta därefter en djup inandning och lägger sedan kraft på ordet den tredje gången för att i ren irritation få till det rätt. Klipper man bort de första två felaktiga uttalen, blir meningen mycket märklig. Det blir som personen helt plötsligt SKRIKER ut ett ord mitt i en mening.
Så ofta klipper jag till ljudet, lyssnar och rättar klipp-punkterna tills det låter naturligt. Går inte det, får det vara kvar i oförändrat skick.
Pauser kortas också ned för att vi blixtsnabbt ska svara varandra i inledningen där det inte låter som vi konverserar. Därefter får konversationen gärna låta mer som just en sådan. Det finns ingen metod att göra det rätt, utan bara att lyssna… lyssna… lyssna… Känns det för det mesta som en ”skjutjärnsdiskussion”, är det perfekt klippt.
En noggrann lyssning
Därefter tar jag paus för att vila hörseln. Sedan lyssnar jag på programmet i sin helhet. Detta gör jag ofta med en JBL bluetooth-högtalare jag har. Denna är inte korrekt i sin ljudåtergivning men tänkt för att demonstrera hur det kan tänkas låta i någons bilstereo eller annan ”smart-speaker”.
I detta läge tar jag också noteringar om saker vi säger som kanske bör föklaras mer noggrannt i våra show notes. Jag noterar även problem med ljudet och kanske brister i samtalet eller i värsta fall en felsägning eller inkorrekt fakta. Jag försöker också sätta mig in i hur en lyssnare kan tänkas förstå vad vi säger. Är vi tillräckligt tydliga? Kan man missförstå oss?
Det är mycket ovanligt att det uppstår en situation när jag måste gå in och klippa om i programmet eller rätta något. Men en del hamnar i show notes.
Mastring
Att ”mastra” är att skapa en färdig processad och redigerad inspelning och lagra den i en form redo för produktion av t.ex. vinylskivor eller CD-skivor. i vårt fall handlar det istället om att skapa ljudfiler och lägga upp dem på nätet.
Jag skapar alltid en .wav-fil i full ljudkvalité och en .mp3-fil med CBR Stereo 192 kbps 48 KHz eftersom det sistnämda är vad vi lägger upp för lyssning. MP3-filen blir normalt runt 20-40 MB beroende på längden på programmet.
Vi har ett konto på Libsyn där vi laddar upp filen och skapar ett nytt avsnitt. Detta schemalägger vi sedan till lämpligt datum efter att vi lagt upp en beskrivande text och en bild. Bilderna skapar Mattias som oftast även skriver beskrivningstexten.
När tiden instundat, trycker Libsyn ut ljudfilen med bilden inbäddad på alla tjänster där man kan nå den som t.ex. YouTube, Soundcloud m.fl. Många tjänster accepterar inte några filer utan bara ett RSS-feed (en textfil kan man säga) där man talar om att det finns ett nytt avsnitt och var man kan ladda ner filen från Libsyns Content Delivery Network. Tjänster som Itunes, Podbean, TuneIn, Spotify och liknande fungerar så och Libsyn fixar även detta.
Slutsats
Det kanske låter märkligt men varje avsnitt tar i genomsnitt tio timmar att producera från planering tills att det ligger ute. I detta ligger bokning av gäster, lokaler, resor, manusskrivning, själva inspelningen, fotografering, redigering, kontrolllysning, skapande av bilder för illustrationer, skrivande av beskrivningar, skapande av show notes och publicering på sociala media.
Sen tillkommer hemsidedesign, kommunikation med lyssnare, lyssna på våra ”konkurrenter”, läsa om om allt som händer på säkerhetssidan, planera kommande poddavsnitt, svettigt läsande och behandlande av lyssnarstatistik. Även fundera på trender, försöka förstå varför vi ökar eller minskar i lyssning och läsa på om poddteknik rent allmänt.
Därutöver åker jag och Mattias ibland ut och föreläser på IT-säkerhetsämnet på diverse seminarier eller gör recensioner av säkerhetslösningar. Vi arbetar även båda på Nordlo Improve med IT-säkerhet och utvecklar tillsammans ett kommande system för automatiserad server- och klientdokumentation i vårt egna företag MoleAnt AB.
Ljudskapande är en viktig bit i det hela för att låta så bra som vi kan givet våra förutsättningar och det är något som tas på blodigt allvar!
Tips: här är en guide i just Ljudteknik jag skrev på den tiden Metusalem gick på jorden.
Hej, hur får ni till signalen från Teams till Zoom H6? Om jag sitter med H6, kopplar jag hörlurarna till datorn för att höra den som sitter på länk, pratar i mickar kopplade till H6? Hur kommer personen på länk in i H6?
//Ville
Det finns två lösningar:
– Skaffa en kabel som går mellan två phonopluggar som passar i H6an (6,3 mm) och en stereokabel med phono (den mindre storleken). Denna kopplar du mellan datorn och Zoomen. Ljudet som går till de du pratar tar du från mikrofonen i datorn eller telefoenen. Denna lösning är enkel, men kan vara dålig om de som är i rummet där podden spelas in sitter långt från varandra. Då hör inte den som är över länken ordentligt. Men det kräver inga förberedelser.
– Skaffa / Bygg en mix-minus-koppling. Denna hindrar ljudet från länken att ledas tillbaka från bandspelaren till den som sitter över länk.
Här finns en del tips:
https://www.youtube.com/watch?v=A8KriG2OTvI
Lycka till!
//Erik